[Algorithm] Trie란?
in Algorithm on DataStructure, Trie
트라이(Trie)란?
trie: 트라이(Trie)란 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조- 원하는 원소를 찾기 위해 자주 이용되는 이진 검색 트리등에서는 원소를 찾는데
O(logN)의 시간이 걸리게 된다.- 문자열의 경우 두 문자열을 비교하기 위해서는 문자열의 길이만큼의 시간이 걸리기 때문에 원하는 문자열을 찾기 위해서는
O(MlogN)의 시간이 걸리게 된다.
- 문자열의 경우 두 문자열을 비교하기 위해서는 문자열의 길이만큼의 시간이 걸리기 때문에 원하는 문자열을 찾기 위해서는
- 반면 Trie의 탐색 복잡도는
O(L). 가장 긴 문자열의 길이만큼 탐색하기 때문- 생성시간 복잡도는 모든 문자열들을 넣어야하니 M개에 대해서 트라이 자료구조에 넣는건 가장 긴 문자열 길이만큼 걸리니 L만큼 걸려서
O(M*L)
- 생성시간 복잡도는 모든 문자열들을 넣어야하니 M개에 대해서 트라이 자료구조에 넣는건 가장 긴 문자열 길이만큼 걸리니 L만큼 걸려서
- 이 단점을 해결하기 위한 문자열 특화 자료구조가 트라이(Trie)이다.
트라이의 작동 원리
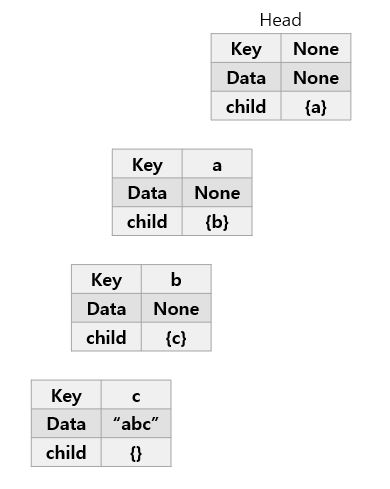
- “abc” -> “ac” -> “car”을 순서대로 저장한다고 가정
- 먼저 “abc”를 넣는다.
- 1-1. 첫번째 문자는 “a”이다. 초기에 trie 자료구조 내에는 아무것도 추가되어있지 않음으로 Head의 자식노드에 “a”를 추가한다.
- 1-2. “a”노드에는 현재 자식이 하나도 없으므로, “b”를 자식노드인 “a”의 자식으로 추가
- 1-3. “c”e도 마찬가지로 “b”의 자식노드로 추가해준다.
- 1-4. “abc”라는 단어가 여기서 끝남을 알리기 위해 현재 노드에 abc라고 표시한다.
- 먼저 “abc”를 넣는다.
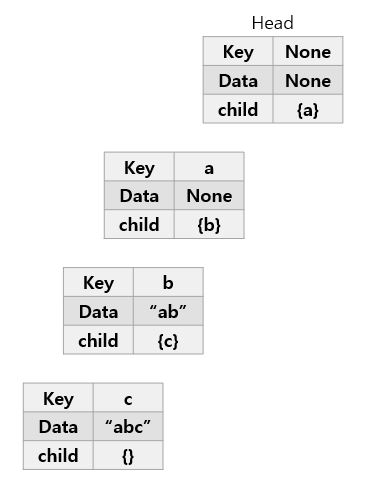
- 2. 다음으로 "ab"를 추가
- 2-1. 현재 Head의 자식 노드로 "a"가 이미 존재한다. 따라서 "a"의 노드를 추가하지 않고 기존에 있던 "a"노드로 이동
- 2-2. "b"도 "a"의 자식노드로 이미 존재한다. "b"노드로 이동한다.
- 2-3. 여기서 "ab"라는 단어가 끝이 남으로, 현재 노드에 ab를 표시한다.
- 
- 3. 마지막으로 "car"를 추가하자.
- 3-1. Head의 자식 노드로, "a"만 존재하고 "c"는 존재하지 않는다. 따라서 "c"를 자식 노드로 추가하자.
- 3-2. "c"의 하위노드가 없음으로 마찬가지로 "a"를 추가한다. "r"에 대해서도 동일하다. "car"가 "r"노드에서 끝남으로 "car"를 표시해준다.
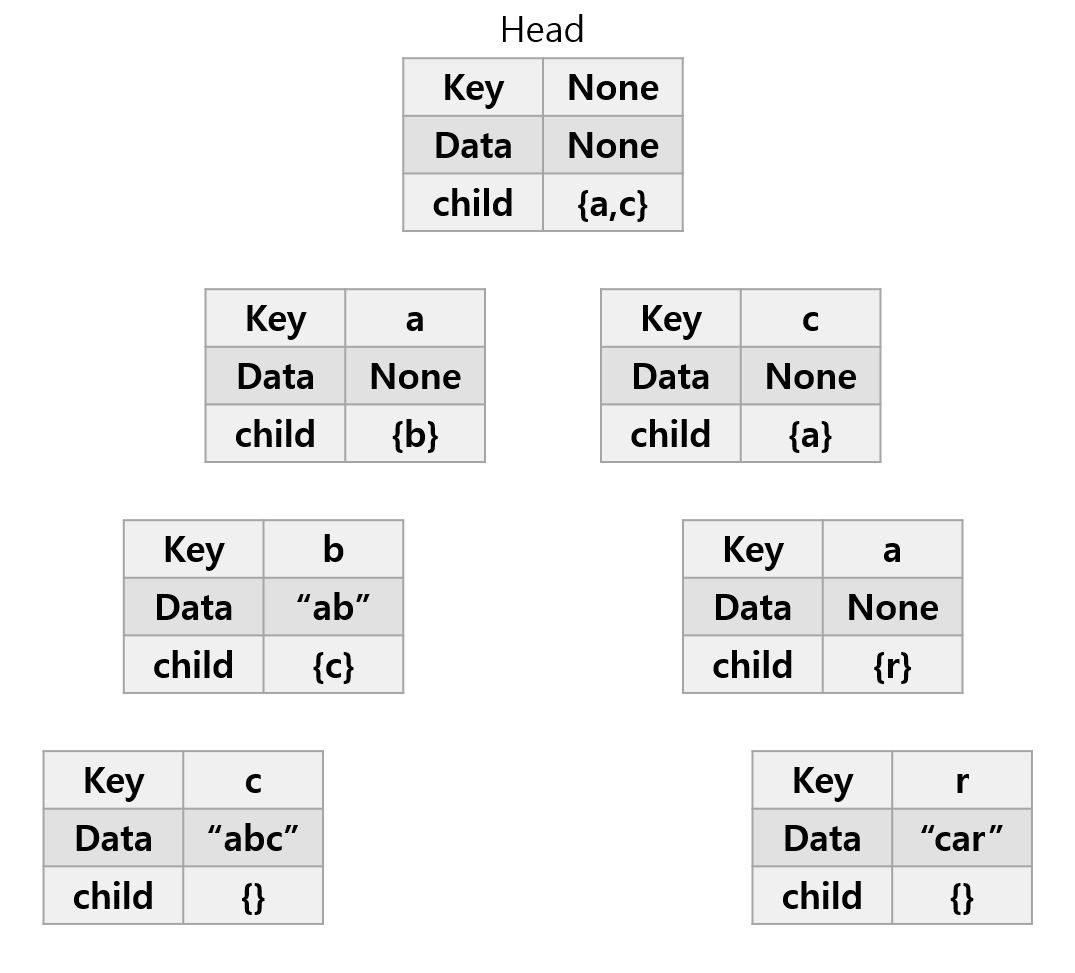
- 이처럼 트라이는 집합에 포함된 문자열의 접두사들에 대응되는 노드들이 서로 연결된 트리.
- 한 문자열에서 다음에 나오는 문자가 현재 문자의 자식 노드가 되고, 빨간색으로 나타낸 노드는 문자열의 끝을 의미한다.
- 트라이의 중요한 속성 중 하나는, 루트에서부터 내려가는 경로에서 만나는 글자들을 모으면 찾고자 하는 문자열의 접두사를 얻을 수 있다는 것이다.
- 예를 들어서 ‘rebro’를 찾는다고 하면 r -> re -> reb -> rebr -> rebro가 되므로 모든 접두사들이 다 구해지게 된다.
- 따라서 각 노드에는 접두사를 저장할 필요 없이 문자 하나만 저장해줘도 충분하다.
트라이 자료구조의 장/단점
- 트라이의 장점은 문자열을 빠르게 찾을 수 있다는 점.
문자열을 집합에 추가하는 경우에도 문자열의 길이만큼 노드를 따라가거나 추가하면 되기 때문에 문자열의 추가와 탐색 모두 O(M)만에 가능하다.
- 반면 트라이의 단점은 필요한 메모리가 너무 크다는 점.
- 문자열이 모두 영소문자로 이루어져있다고 해도 자식 노드를 가리키는 26개의 포인터를 저장해야 한다.
- 최악의 경우에는 집합에 포함되는 문자열들의 길이의 총합만큼 노드가 필요하므로, 총 메모리는 O(포인터 크기 * 포인터 배열 개수 * 총 노드의 개수)
- 만약 1000자리 문자열이 1000개만 들어온다고 하더라고 100만개의 노드가 필요. 포인터의 크기가 8 Byte라고 하면 200MB가 필요.
Python에서 Trie 구현하기
class Node(object):
def __init__(self, key, data=None):
self.key = key
self.data = data
self.children = {}
class Trie(object):
def __init__(self):
self.head = Node(None)
# 문자열 삽입
def insert(self, string):
curr_node = self.head
# 삽입할 string 각각의 문자에 대해 자식 Node를 만들며 내려간다.
for char in string:
# 자식 Node들 중 같은 문자가 없으면 Node 새로 생성
if char not in curr_node.children:
curr_node.children[char] = Node(char)
# 같은 문자가 있으면 노드를 따로 생성하지 않고, 해당 노드로 이동
curr_node = curr_node.children[char]
#문자열이 끝난 지점의 노드의 data값에 해당 문자열을 입력
curr_node.data = string
# 문자열이 존재하는지 search
def search(self, string):
#가장 아래에 있는 노드에서 부터 탐색 시작
curr_node = self.head
for char in string:
if char in curr_node.children:
curr_node = curr_node.children[char]
else:
return False
#탐색이 끝난 후 해당 노드의 data값이 존재한다면
#문자가 포함되어있다는 뜻이다.
if curr_node.data != None:
return True
Reference
[ https://youseop.github.io/2020-11-09-BAEKJOON-14425%EB%AC%B8%EC%9E%90%EC%97%B4%EC%A7%91%ED%95%A9]( https://youseop.github.io/2020-11-09-BAEKJOON-14425%EB%AC%B8%EC%9E%90%EC%97%B4%EC%A7%91%ED%95%A9)
