[Algorithm] 다익스트라 알고리즘
다익스트라 알고리즘이란?
- 특정 노드에서 출발하여 다른 모든 노드로 가는 최단 경로를 계산
- 다익스트라 최단 경로 알고리즘은 음의 간선이 없을 때 정상적으로 동작
- 현실 세계의 도로(간선)은 음의 간선으로 표시되지 않는다.
- 다익스트라 최단 경로 알고리즘은 그리디 알고리즘으로 분류됨
- 매 상황에서 가장 비용이 적은 노드를 선택해 임의의 과정을 반복
- 알고리즘 동작 과정에서 최단 거리 테이블은 각 노드에 대한 현재까지의 최단 거리 정보를 가지고 있다.
- 단계를 거치며 한 번 처리된 노드의 최단 거리는 고정되어 더 이상 바뀌지 않는다.
- 한 단계당 하나의 노드에 대한 최단 거리를 확실히 찾는 것으로 이해할 수 있다.
다익스트라 알고리즘의 동작 과정
- 1) 출발 노드를 설정
- 2) 최단 거리 테이블을 초기화
- 3) 방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택.
- 4) 해당 노드를 거쳐 다른 노드로 가는 비용을 계산하여 최단 거리 테이블을 갱신
- 5) 위 과정에서 3번 4번을 반복
실제 예시
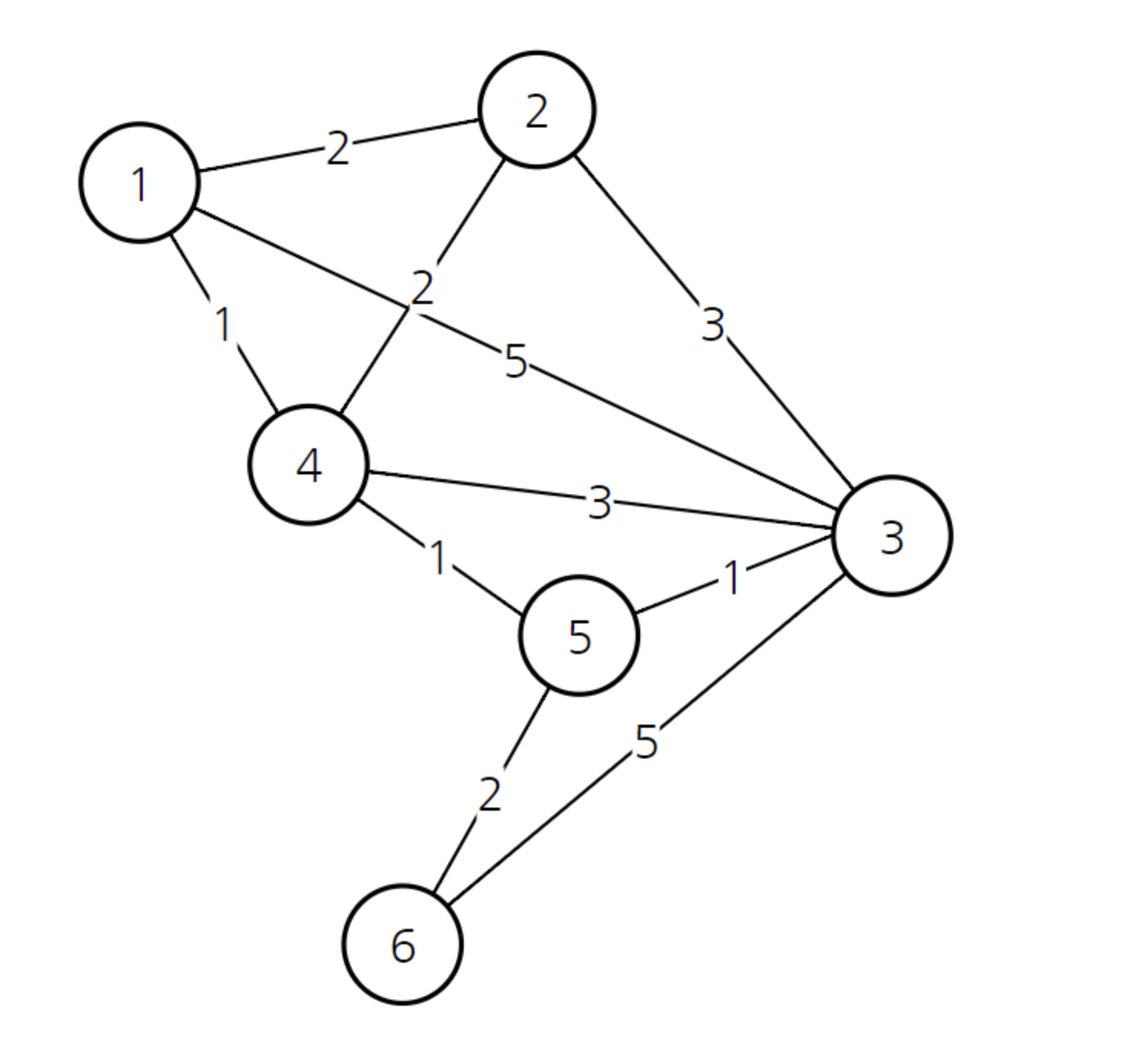
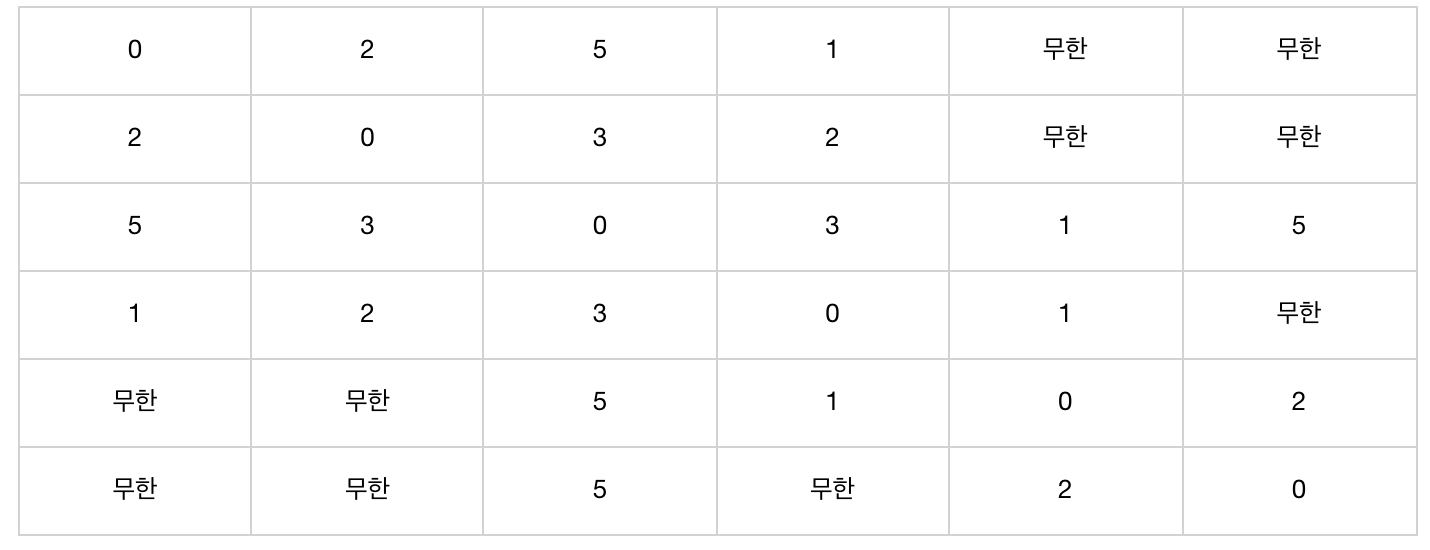
위와 같은 그래프가 있습니다. 이러한 그래프는 실제로 컴퓨터 안에서 처리할 때 이차원 배열 형태로 처리해야 합니다. 아래 표의 의미는 특정 행에서 열로 가는 비용입니다. 보시면 1행 3열의 값이 5입니다. 이것은 1번 노드에서 3번 노드로 가는 비용이 5라는 것
이 상태에서 1번 노드를 선택합니다.
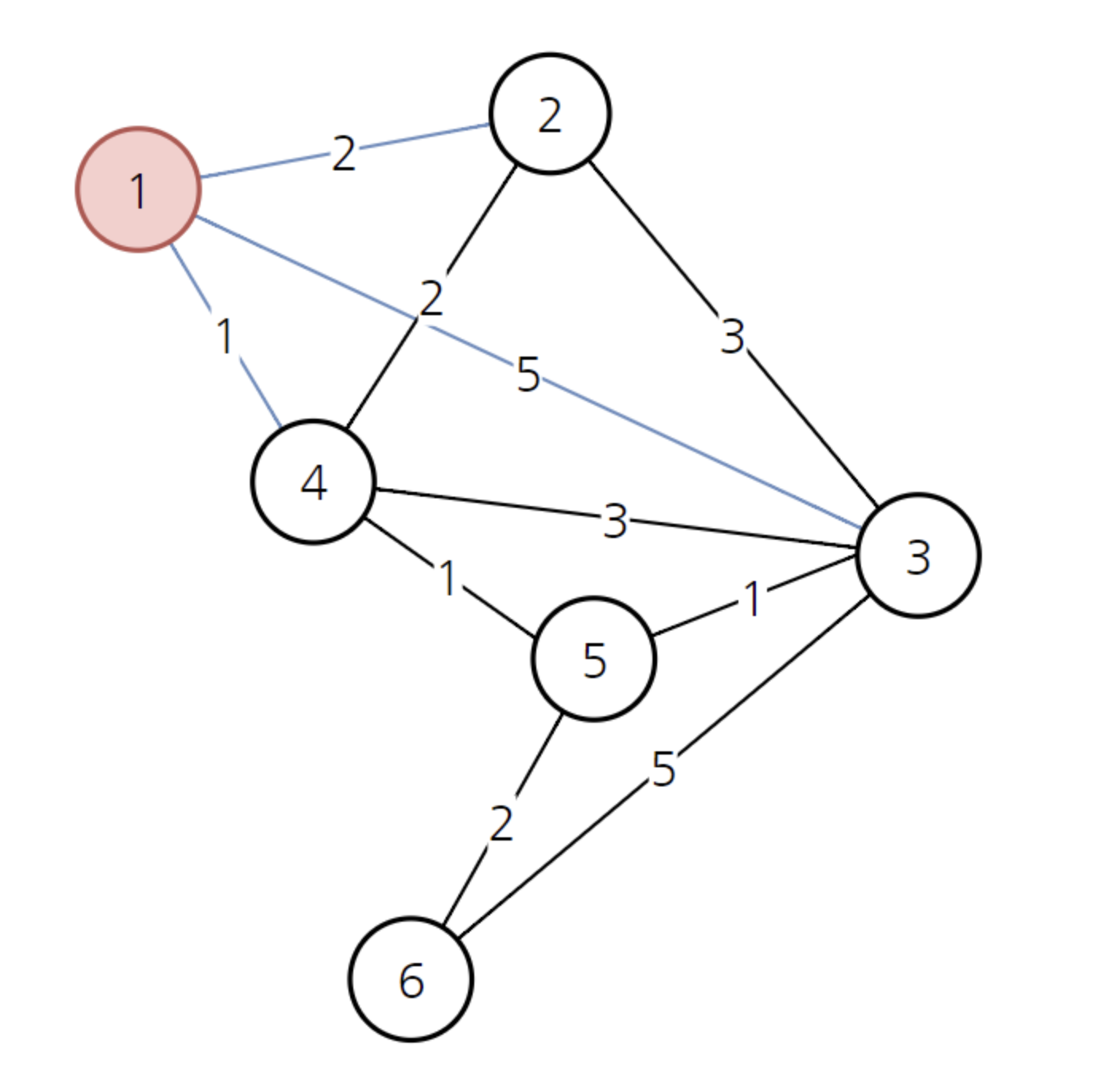
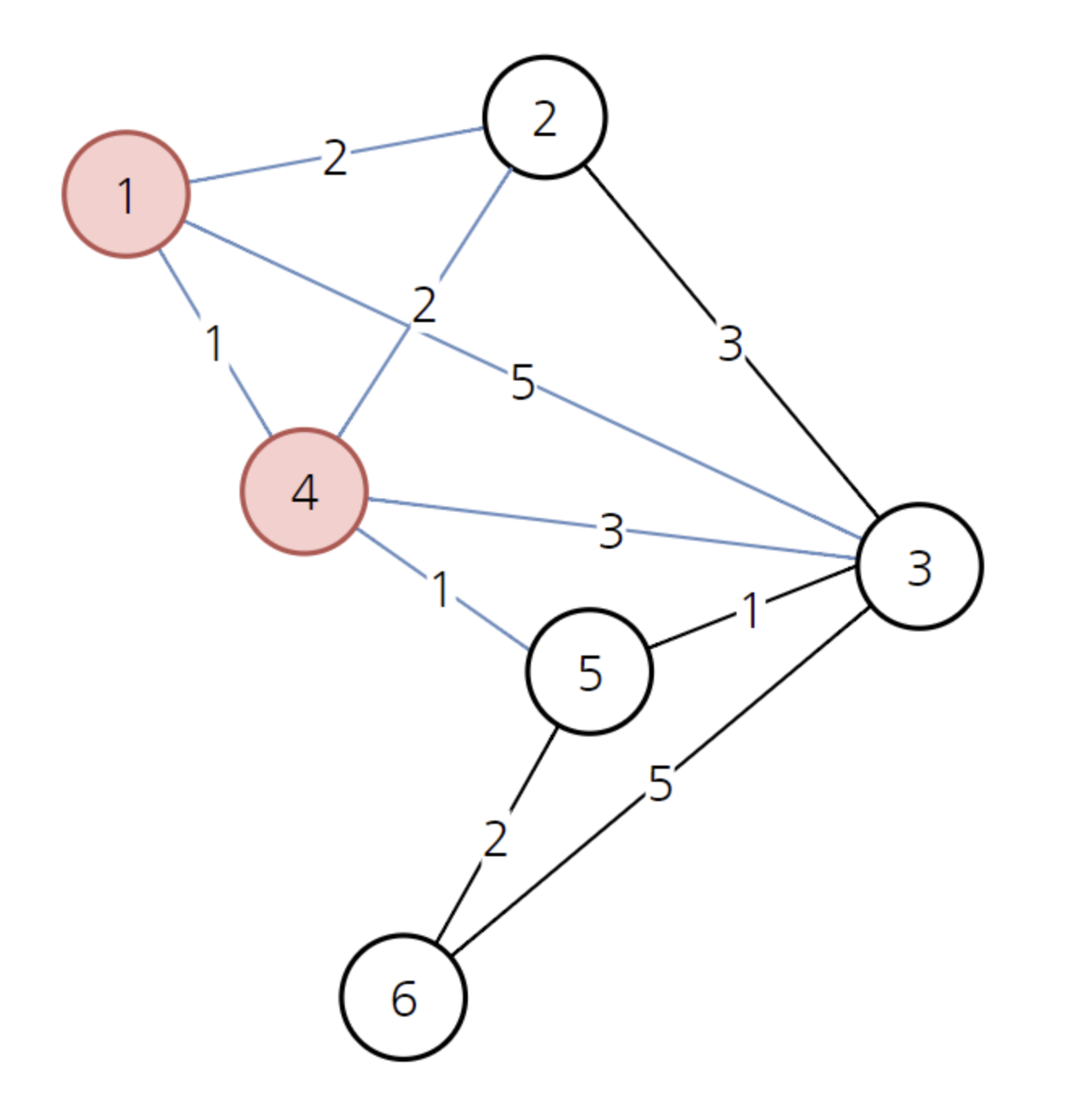
위와 같이 노드 1을 선택한 상태고, 그와 연결된 세 개의 간선을 확인한 상태입니다. 1번 노드에서 다른 정점으로 가는 최소 비용은 다음과 같습니다. 배열을 만든 뒤에는 이 취소 비용 배열을 계속해서 갱신할 것입니다. 현재 방문하지 않은 노드 중에서 가장 비용이 적은 노드는 4번 노드입니다.

따라서 위 배열의 상태를 고려하여 4번 노드가 선택되었습니다. 4번 노드를 거쳐서 가는 경우를 모두 고려하여 최소 비용 배열을 갱신합니다.
보면 기존에 5로 가는 최소 비용은 무한이였습니다. 하지만 4를 거쳐서 5로 가는 경우는 비용이 2이므로 최소 비용 배열을 갱신해줍니다. 또한 4를 거쳐서 3으로 가는 경우는 비용이 4이므로 기존보다 저렴합니다. 따라서 최소 비용 배열을 갱신해줍니다. 결과적으로 아래와 같습니다.

이제 다음으로 방문하지 않은 노드 중에서 가장 비용이 적은 노드는 2번 노드입니다.
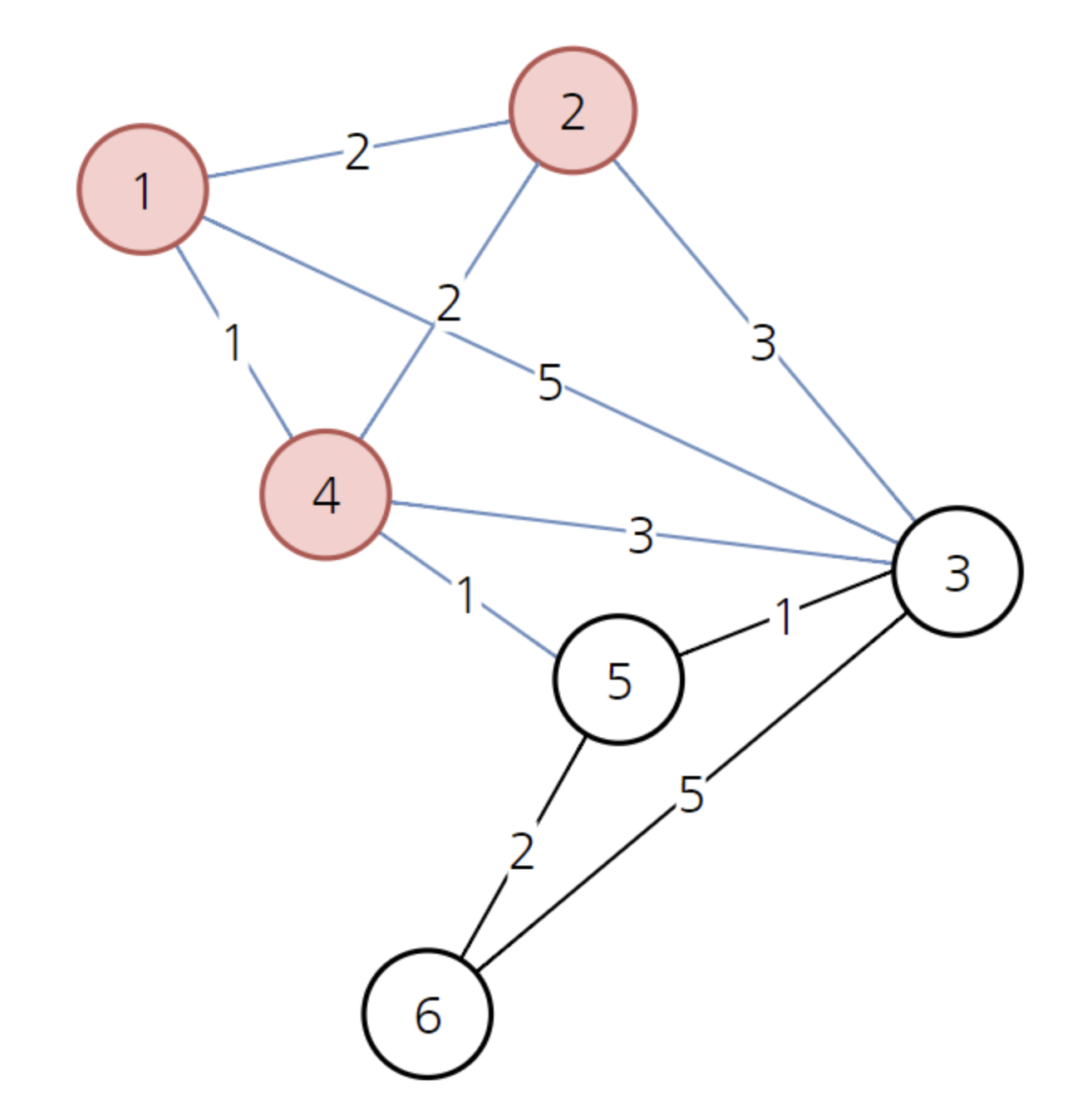
2를 거쳐서 가더라도 비용이 갱신되는 경우가 없습니다. 배열은 그대로 유지합니다.

다음으로 방문하지 않은 노드 중에서 가장 비용이 가장 적은 노드는 5번째 노드입니다.
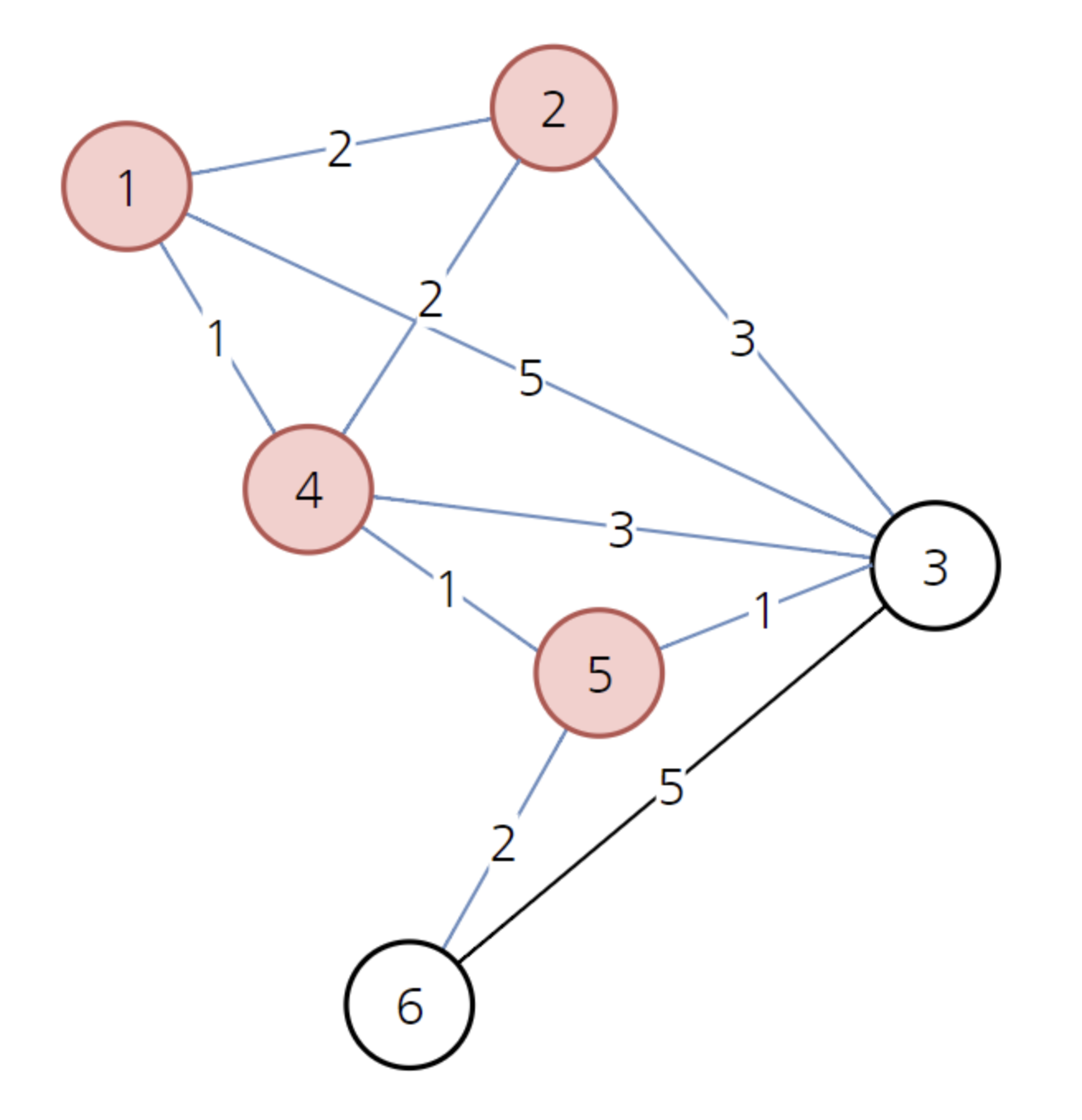
위와 같이 5를 거쳐서 3으로 가는 경우 경로의 비용이 3이므로 기존의 4보다 더 저렴합니다. 따라서 노드 3으로 가는 비용을 3으로 바꾸면 됩니다. 또한 5를 거쳐서 6으로 가는 경우 경로의 비용이 4로 기존의 무한보다 더 저렴합니다. 따라서 노드 6으로 가는 비용을 4로 바꾸면 됩니다.

이후에 방문하지 않은 노드 중에서 가장 저혐한 노드 3을 방문합니다.
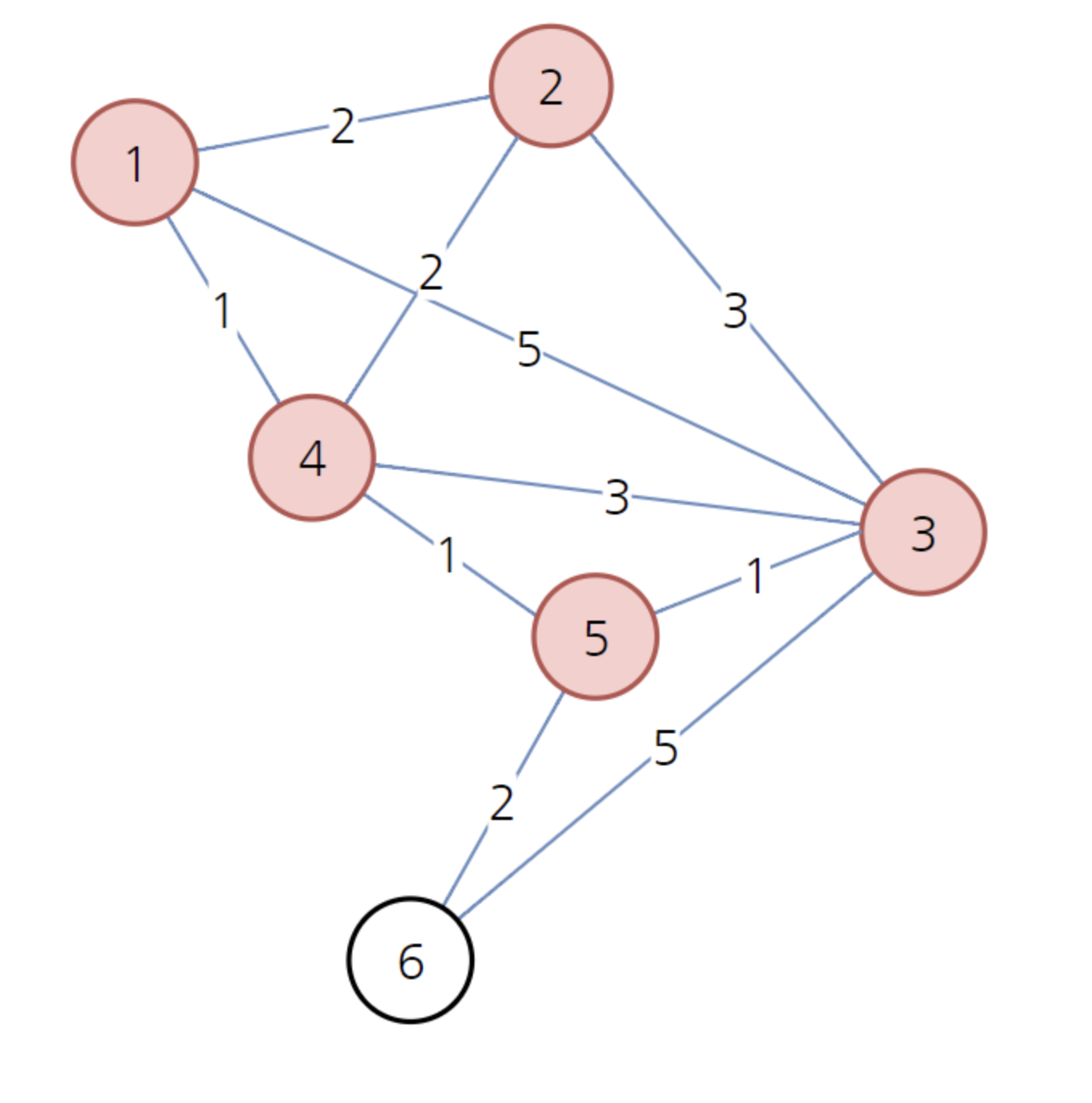
최소 비용 갱신은 일어나지 않습니다.

이제 마지막으로 남은 노드 6을 살펴봅니다.
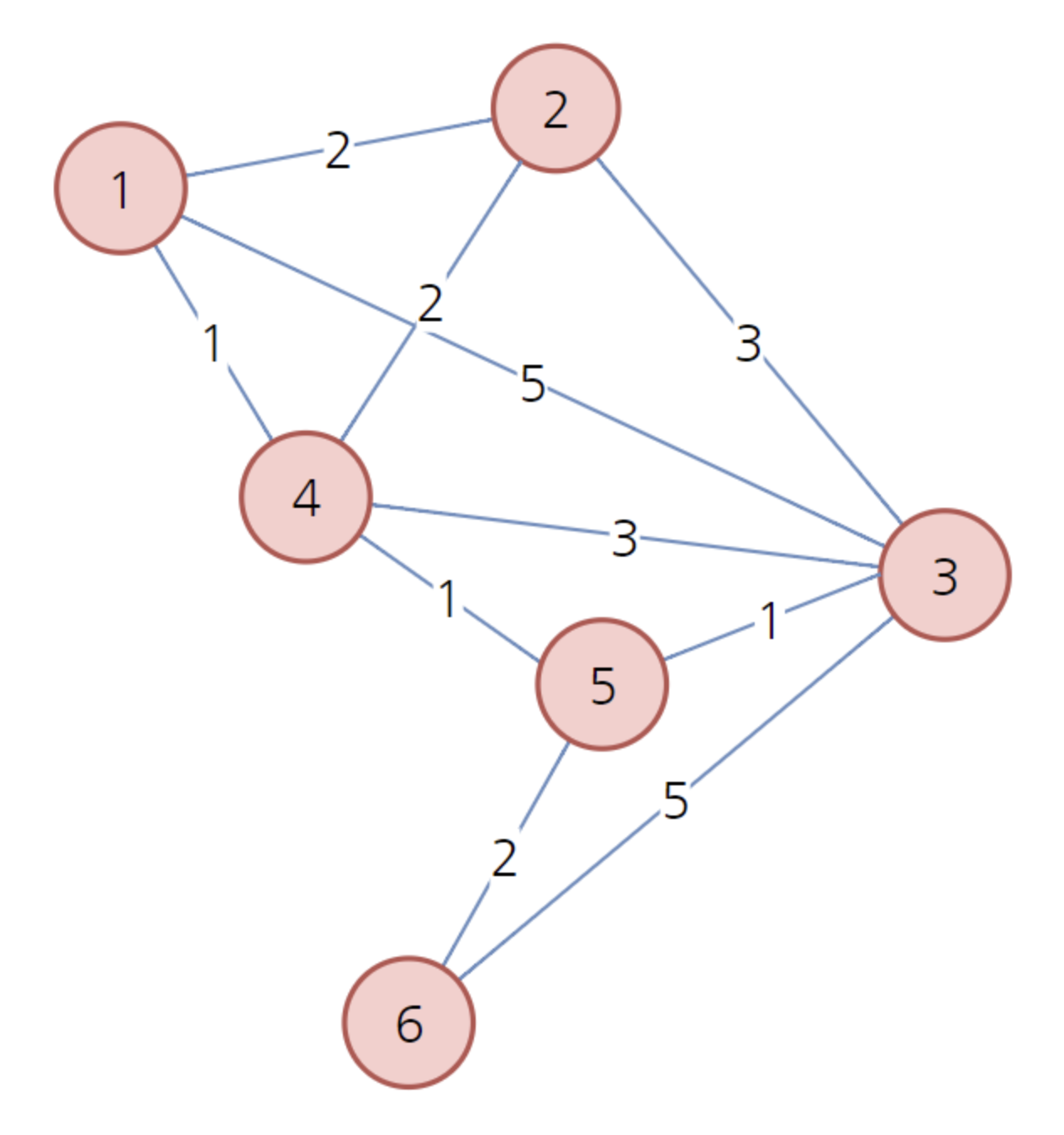
노드 6을 방문한 뒤에도 결과는 같습니다. 따라서 최종 배열은 다음과 같이 형성됩니다.

시간복잡도
- 총 O(V) 번에 걸쳐서 최단 거리가 가장 짧은 노드를 매번 선형 탐색해야 합니다.
- 따라서 전체 시간 복잡도는 O(V**2) 입니다.
- 현재 가장 가까운 노드를 저장해 놓기 위해서 힙 자료구조를 추가적으로 이용합니다.
- 이때 시간복잡도는 O(VlogV)
파이썬 코드
import heapq
graph = {
'A': {'B': 2, 'C': 5, 'D': 1},
'B': {'D': 2, 'C' : 3},
'C': {'B': 3, 'F': 5},
'D': {'C': 3, 'E': 1},
'E': {'C': 1, 'F': 2},
'F': {}
}
def dijkstra(graph, start):
distances = {node: float('inf') for node in graph} # start로 부터의 거리 값을 저장하기 위함
distances[start] = 0 # 시작 값은 0이어야 함
queue = []
heapq.heappush(queue, [distances[start], start]) # 시작 노드부터 탐색 시작 하기 위함.
while queue: # queue에 남아 있는 노드가 없으면 끝
current_distance, current_destination = heapq.heappop(queue) # 탐색 할 노드, 거리를 가져옴.
if distances[current_destination] < current_distance:
# 현재 노드가 이미 처리된 노드라면
# 기존에 있는 거리보다 길다면, 볼 필요도 없음
continue
for new_destination, new_distance in graph[current_destination].items():
distance = current_distance + new_distance # 해당 노드를 거쳐 갈 때 거리
if distance < distances[new_destination]: # 알고 있는 거리 보다 작으면 갱신
distances[new_destination] = distance
heapq.heappush(queue, [distance, new_destination]) # 다음 인접 거리를 계산 하기 위해 큐에 삽입
return distances
print(dijkstra(graph, start)) # {'A': 0, 'B': 2, 'C': 3, 'D': 1, 'E': 2, 'F': 4}
