[Python] 후보키
Programmers : 후보키
문제 설명
프렌즈대학교 컴퓨터공학과 조교인 제이지는 네오 학과장님의 지시로, 학생들의 인적사항을 정리하는 업무를 담당하게 되었다.
그의 학부 시절 프로그래밍 경험을 되살려, 모든 인적사항을 데이터베이스에 넣기로 하였고, 이를 위해 정리를 하던 중에 후보키(Candidate Key)에 대한 고민이 필요하게 되었다.
후보키에 대한 내용이 잘 기억나지 않던 제이지는, 정확한 내용을 파악하기 위해 데이터베이스 관련 서적을 확인하여 아래와 같은 내용을 확인하였다.
- 관계 데이터베이스에서 릴레이션(Relation)의 튜플(Tuple)을 유일하게 식별할 수 있는 속성(Attribute) 또는 속성의 집합 중, 다음 두 성질을 만족하는 것을 후보 키(Candidate Key)라고 한다.
- 유일성(uniqueness) : 릴레이션에 있는 모든 튜플에 대해 유일하게 식별되어야 한다.
- 최소성(minimality) : 유일성을 가진 키를 구성하는 속성(Attribute) 중 하나라도 제외하는 경우 유일성이 깨지는 것을 의미한다. 즉, 릴레이션의 모든 튜플을 유일하게 식별하는 데 꼭 필요한 속성들로만 구성되어야 한다.
제이지를 위해, 아래와 같은 학생들의 인적사항이 주어졌을 때, 후보 키의 최대 개수를 구하라.
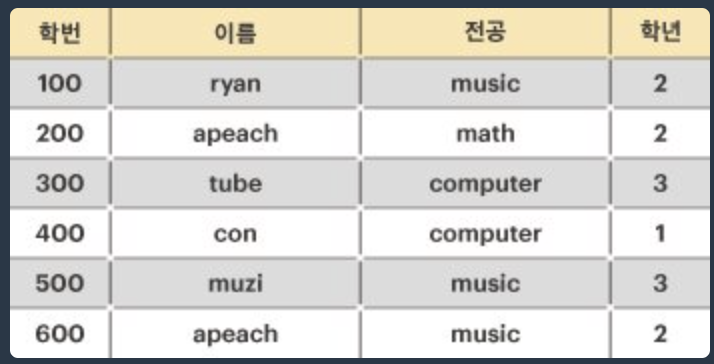
위의 예를 설명하면, 학생의 인적사항 릴레이션에서 모든 학생은 각자 유일한 “학번”을 가지고 있다. 따라서 “학번”은 릴레이션의 후보 키가 될 수 있다. 그다음 “이름”에 대해서는 같은 이름(“apeach”)을 사용하는 학생이 있기 때문에, “이름”은 후보 키가 될 수 없다. 그러나, 만약 [“이름”, “전공”]을 함께 사용한다면 릴레이션의 모든 튜플을 유일하게 식별 가능하므로 후보 키가 될 수 있게 된다. 물론 [“이름”, “전공”, “학년”]을 함께 사용해도 릴레이션의 모든 튜플을 유일하게 식별할 수 있지만, 최소성을 만족하지 못하기 때문에 후보 키가 될 수 없다. 따라서, 위의 학생 인적사항의 후보키는 “학번”, [“이름”, “전공”] 두 개가 된다.
릴레이션을 나타내는 문자열 배열 relation이 매개변수로 주어질 때, 이 릴레이션에서 후보 키의 개수를 return 하도록 solution 함수를 완성하라.
제한 사항
- relation은 2차원 문자열 배열이다.
- relation의 컬럼(column)의 길이는 1 이상 8 이하이며, 각각의 컬럼은 릴레이션의 속성을 나타낸다.
- relation의 로우(row)의 길이는 1 이상 20 이하이며, 각각의 로우는 릴레이션의 튜플을 나타낸다.
- relation의 모든 문자열의 길이는 1 이상 8 이하이며, 알파벳 소문자와 숫자로만 이루어져 있다.
- relation의 모든 튜플은 유일하게 식별 가능하다.(즉, 중복되는 튜플은 없다.)
입출력 예

문제에 들어가기 앞서 Set에 대해서 정리해보겠습니다.
Python은 set이라는 형태로 집합 자료구조를 제공합니다. 다음과 같은 상황에 집합을 사용합니다.
- 데이터의 중복이 없어도 될때
- 집합에 담긴 모든 데이터는 유니크합니다.
- 예를 들어, 집합에 5를 2번 넣어도 집합은 자신이 가진 원소 중 5는 하나만 있다고 생각합니다.
- 다루는 데이터의 삽입/삭제/서치가 자주 일어날때. 특히 다루는 데이터가 정수가 아닐 때
- 숫자형 데이터는 list에서 insert를 통해 접근할 수 있습니다. 집합은 문자열 등 리스트의 index로 활용하지 못하는 데이터를 빠르게 탐색할 때 유용합니다.
- 예를 들어, 리스트에 “abc”라는 원소가 있는지 알아내려면 O(N)이 걸립니다. 반면 집합은 O(1)이 소요됩니다.
- 교집합, 합집합, 차집합등을 구해야 할 때
- 파이썬의 집합은 수학에서 말하는 집합이 가진 대부분의 기능을 제공합니다.(차집합, 교집합…)
집합의 Time Complexity
| Operation | 예시 | Time Complexity |
|---|---|---|
| 탐색 | “abc” in my_set | O(1) |
| 제거 | my_set.discard | O(1) |
| 합집합 | set1 | set2 | O(len(set1) + len(set2)) |
| 교집합 | set1 & set2 | O(min(len(set1),len(set2))) |
| 차집합 | set1 - set2 | O(len(set1)) |
add, discard
집합에 원소를 넣을 때에는 add 메소드를 이용합니다.
my_set = set()
my_set.add(3)
my_set.add("연식")
my_set # {3, '연식'}
집합에서 원소를 지우려면 discard 메소드를 이용합니다.
# 원소 제거 예시
my_set = set([1,2,3,4,5])
my_set.discard(1)
my_set # {2, 3, 4, 5}
집합 - 합/차/교집합 등 집합 관련 Operation
- 합집합은
|를 사용
set1 = set([1,2,3,4,5])
set2 = set([4,5,6,7,8])
set1 | set2 # {1, 2, 3, 4, 5, 6, 7, 8}
- 차집합은
-를 사용
set1 = set([1,2,3,4,5])
set2 = set([4,5,6,7,8])
set1 - set2 # {1, 2, 3}
- 교집합은
&를 사용
set1 = set([1,2,3,4,5])
set2 = set([4,5,6,7,8])
set1 & set2 # {4, 5}
풀이
candidates리스트에 모든 컬럼 조합을 담는다.candidates에서 각 원소를 하나씩 뽑고set을 통해 중복값이 있는지 확인. 만약set을 했는데도 그 길이가 달라지지 않는다면final에 그 조합을 담는다. (유일성 체크)answer에final을 복제한다.final내에 (0,1)과 (0,1,2)가 있을때 (0,1,2)안에 (0,1)이 포함되어 있으므로 (0,1,2)는 최소성이 만족하지 않는다. 각 원소가 다른 원소에 포함되어있는지 확인하고, 확인된다면answer에서 그 값을 삭제한다.len(answer)를 리턴한다.
from itertools import combinations
def solution(relation):
n_row = len(relation)
n_col = len(relation[0])
candidates = []
final = []
for i in range(1,n_col+1):
candidates.extend(combinations(range(n_col),i))
# 모든 컬럼 조합을 담는다. 컬럼이 2개면 [(0), (1), (0,1)]
for keys in candidates:
tmp = [tuple([rows[key] for key in keys]) for rows in relation]
# tmp : 컬럼 index에 해당되는 컬럼값들의 모임
if len(set(tmp)) == n_row:
# set으로도 그 길이가 줄어들지 않는다면, 중복이 없다는듯.
final.append(keys)
# 중복이 없는 경우(유일성을 만족하는 경우) final에 담는다.
answer = set(final[:])
for i in range(len(final)-1):
# 최소성 check를 위해, 해당 원소가 다른 원소에 포함되어있는지 확인.
for j in range(i+1,len(final)):
if set(final[i]) == set(final[i]) & set(final[j]):
# 만약 포함되어 있다면 더 큰 원소를 answer에서 삭제함.
answer.discard(final[j])
return len(answer)
